从零实现 Agent 循环 — 一个 while 循环撑起整个智能体
最近在做 BareAgent 这个项目的时候,最大的一个感受是:Agent 系统的核心其实没有大家想象的那么复杂。剥掉所有花哨的外壳,它就是一个循环——调模型、拿工具调用、执行、把结果塞回去,然后再调一次模型。
听起来很简单,但在实际工程里把这个循环做得稳定,比做得"聪明"重要得多。
循环的本质
如果让我用最简洁的方式描述 BareAgent 的核心,大概就是这张图:
LLM → tool_calls → permission check → handler execution → tool_result → LLM
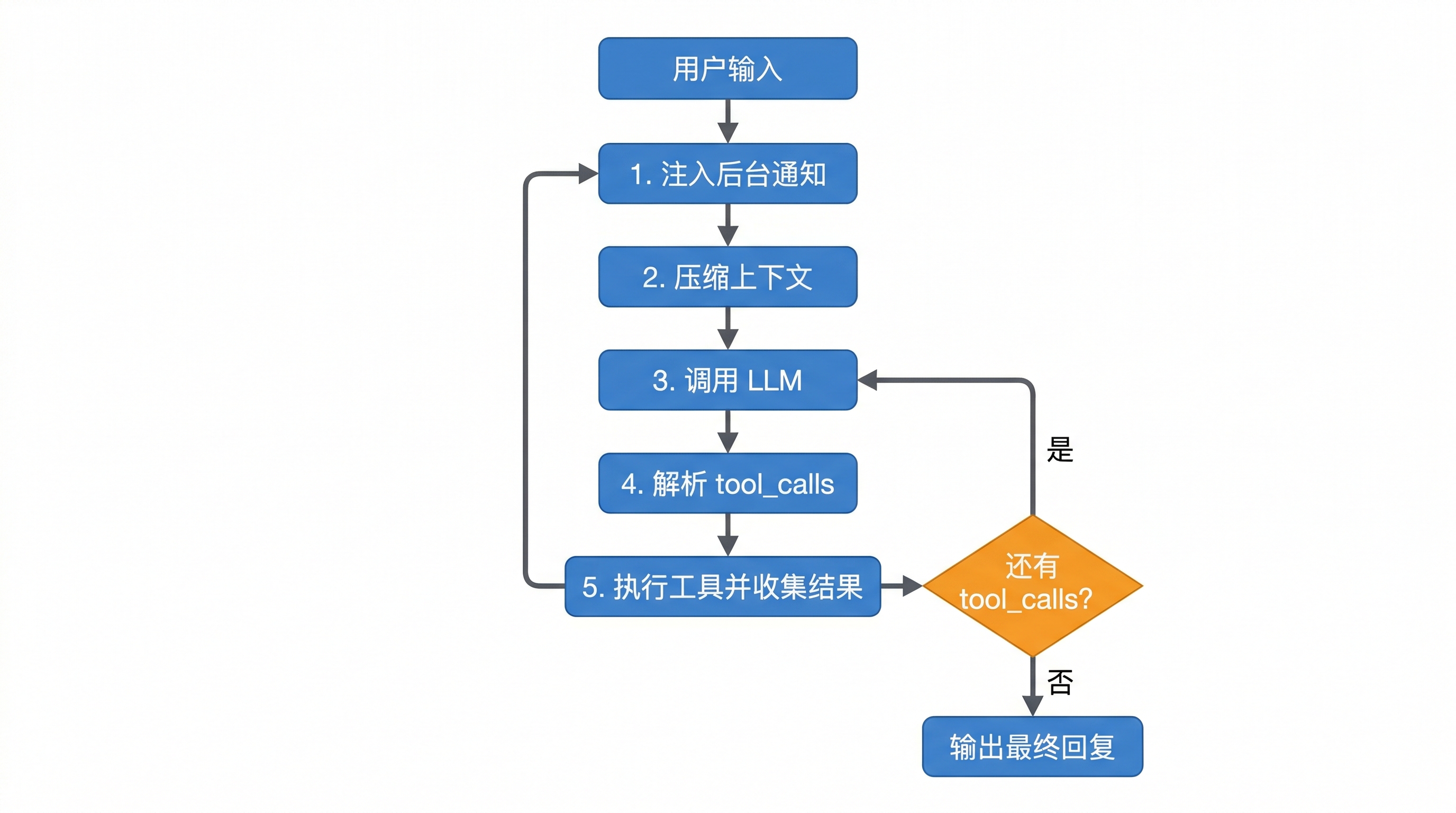
对应到实际代码里,agent_loop() 的主干清爽得有些出人意料:
def agent_loop(
provider, messages, tools, handlers,
permission=None, compact_fn=None, bg_manager=None,
stream=False, console=None, max_iterations=200,
) -> str:
compact = compact_fn or (lambda _messages: None)
for _iteration in range(max_iterations):
compact(messages)
response = provider.create(messages=messages, tools=tools)
messages.append(response.to_message())
if not response.has_tool_calls:
return response.text or ""
results = []
for call in response.tool_calls:
handler = handlers.get(call.name)
if handler is None:
results.append(_tool_result(call.id, f"Unknown tool: {call.name}", is_error=True))
continue
try:
output = handler(**call.input)
except Exception as exc:
output = f"Error: {type(exc).__name__}: {exc}"
results.append(_tool_result(call.id, output, is_error=True))
continue
results.append(_tool_result(call.id, output))
messages.append({"role": "user", "content": results})
raise LLMCallError(f"Agent loop exceeded {max_iterations} iterations")
我精简掉了流式处理、权限检查和 UI 打印的部分,但骨架就是这么一回事。整个 agent_loop() 就是一个 for 循环,每轮做四件事:
- 压缩(如果需要的话)
- 调一次 LLM
- 如果没有工具调用就返回
- 否则逐个执行工具,把结果喂回去
这个结构有个我很喜欢的特性:它是无状态的。所有上下文都存在 messages 列表里,循环本身不持有任何会话状态。这意味着你随时可以从外面往 messages 里注入东西(比如后台任务通知),循环自己不需要知道那些消息是怎么来的。
错误不能让循环崩掉
一个 Agent 在工作过程中,工具调用失败是常态,不是异常。文件可能不存在、命令可能超时、正则可能写错——这些事情天天发生。
如果每次工具失败都让 agent 循环直接炸掉,那这个系统基本没法用。所以 BareAgent 的策略很明确:异常变 tool_result,让模型自己决定怎么办。
try:
output = handler(**call.input)
except Exception as exc:
output = f"Error: {type(exc).__name__}: {exc}"
results.append(_tool_result(call.id, output, is_error=True))
continue
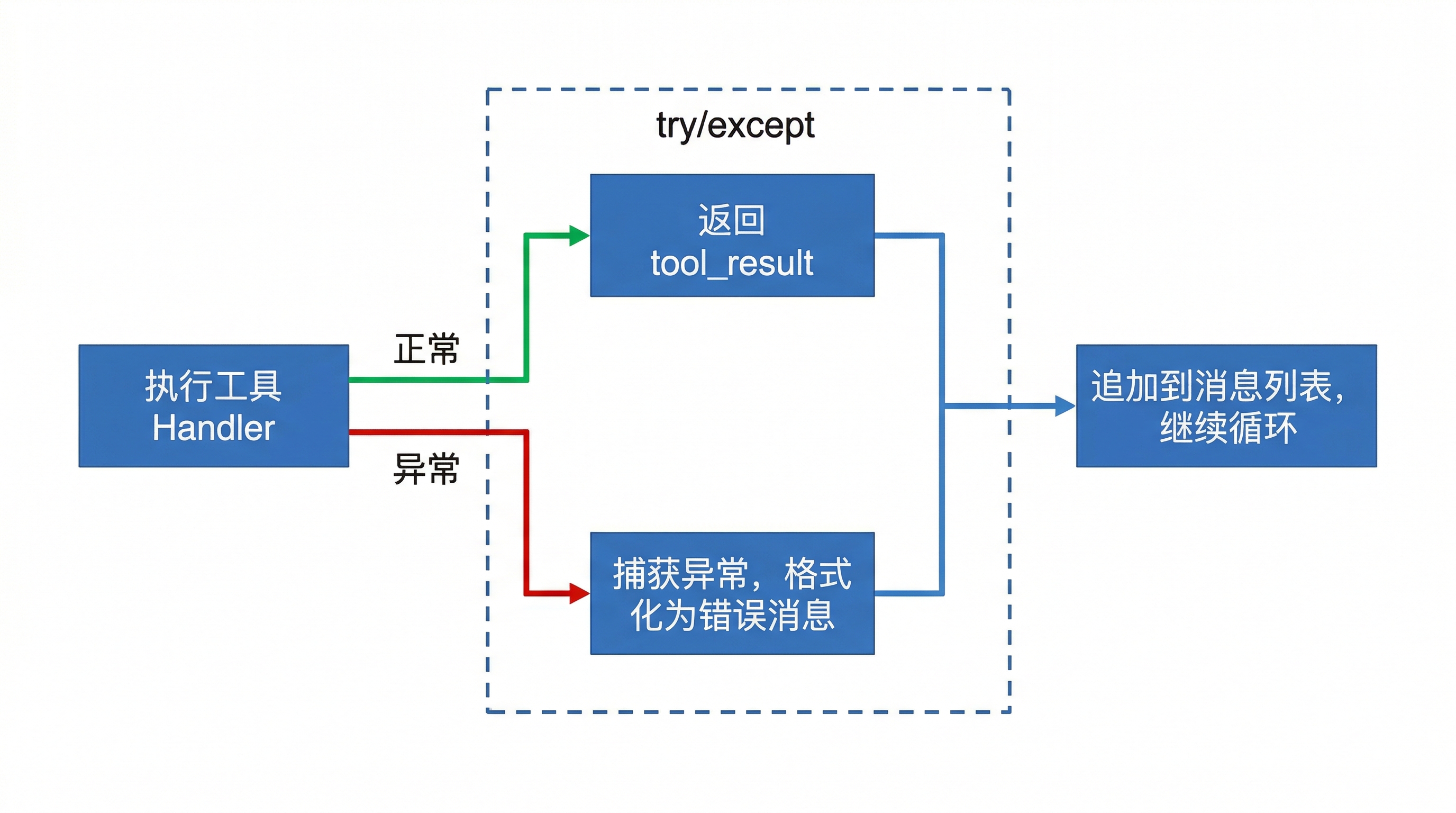
is_error=True 这个标记会告诉模型"这个工具调用出了问题",然后模型可以选择:
- 换个参数重试
- 换个工具
- 直接跟用户说"我搞不定"
这个设计刚开始写的时候觉得理所当然,后来才发现不少开源项目在工具异常时是直接 raise 的,导致一次错误就丢失整段对话上下文。把异常"软化"成消息是一个小决定,但对稳定性的影响巨大。
200 次迭代上限
for _iteration in range(max_iterations):
...
raise LLMCallError(f"Agent loop exceeded {max_iterations} iterations")
为什么是 200?说实话,没有什么科学依据。但这个数字需要:
- 足够大,让 Agent 能完成真正复杂的任务(涉及几十个文件的重构、跑完一轮测试再修 bug 之类的)
- 有上限,避免模型陷入死循环(比如不停重试一个永远会失败的命令)
200 轮,按每轮一次工具调用算,已经足够大了。我用了一段时间下来,正常任务很少超过 50 轮,真到 200 的时候基本都是模型在兜圈子。
子智能体的上限会更低——只读的探索型 agent 限制在 50 轮就够了,没必要给它和主循环一样的预算。
流式输出:generator with return value
流式输出是个工程细节,但做起来比预想的麻烦。问题在于:流式路径需要一边往外吐文本,一边攒出最终的完整响应。
Python 的 generator 有个不太常用的特性:StopIteration 的 value 属性可以携带返回值。BareAgent 的 provider 就是利用这个机制:
def create_stream(self, messages, tools, **kwargs):
with self.client.messages.stream(**params) as stream:
for event in stream:
if event.type == "content_block_delta":
yield StreamEvent(type="text", text=event.delta.text)
# ...
return self._parse_response(stream.get_final_message())
yield 负责实时推送文本片段,return 负责在流结束时给出完整的 LLMResponse。消费端通过捕获 StopIteration 来拿到这个返回值:
try:
event = next(stream_iter)
except StopIteration as stop:
response = stop.value # 这就是最终的 LLMResponse
这个模式在 Python 社区不算常见,但对于"既要流式又要最终结果"的场景特别合适。比直接返回一个 tuple 或者用回调函数干净得多。
不过也踩过一个坑:不是所有 provider 都支持流式。如果 create_stream() 抛了 NotImplementedError,或者在第一个事件之前就报错了,需要自动回退到非流式模式:
try:
stream_iter = provider.create_stream(messages=messages, tools=tools)
except Exception as exc:
if isinstance(exc, NotImplementedError):
return provider.create(messages=messages, tools=tools), False, set()
raise
但如果流已经开始吐内容了,中途断掉就不能静默回退——那种情况下用户已经看到了部分输出,回退会造成混乱。
工具结果的统一格式
工具执行完以后,结果需要包装成模型能理解的格式:
def _tool_result(tool_use_id, output, *, is_error=False):
result = {
"type": "tool_result",
"tool_use_id": tool_use_id,
"content": _stringify_output(output),
}
if is_error:
result["is_error"] = True
return result
_stringify_output() 做的事情也很朴素:字符串原样保留,None 变空字符串,其他东西 JSON 序列化。这种"尽可能不加工"的策略让工具输出能自然地流入下一轮对话。
一个设计上的小选择是:所有工具结果被打包成一条 role="user" 的消息。这是因为 Anthropic 的 API 要求 tool_result 必须出现在 user turn 里。虽然从语义上看,工具结果既不是"用户说的"也不是"助手说的",但 API 就是这么设计的,没得选。
后台任务注入
每轮循环开始前,还有一个不显眼但很关键的步骤:
for _iteration in range(max_iterations):
_run_background(bg_manager, messages)
compact(messages)
# ...
_run_background() 的作用是把已完成的后台任务结果塞进消息历史。它不执行后台任务——那是 BackgroundManager 的事。它只是每轮检查一下"有没有什么后台结果已经出来了",如果有就注入进去。
这样模型在下一次被调用时,就能看到后台任务的结果,决定是继续等还是换个策略。整个注入逻辑对循环主体是透明的。
何时结束
循环只有两种正常退出方式:
- 模型不再调工具 —
response.has_tool_calls为 False,循环返回文本 - 到达迭代上限 — 抛出
LLMCallError
没有第三种。模型调用失败也是直接 raise,不会静默吞掉。
一个容易忽略的点:agent_loop() 的返回值只是"最后一轮 assistant 的文本输出",不是整段对话历史。真正完整的上下文始终保留在传入的 messages 列表里。所以调用方如果想看完整对话记录,看 messages 就行,不需要从返回值里拼。
回头看
写完整个循环之后再审视,最让我满意的不是某个具体的技术选择,而是整体的简单度。这个循环大概 200 行代码,就把 LLM 调用、工具执行、权限检查、流式输出、后台注入和上下文压缩全串起来了。
没有复杂的状态机,没有事件总线,没有中间件管线。就是一个循环,每轮做该做的事,然后看模型下一步想干什么。
当然,这种简单是有代价的——它不支持并行工具调用(虽然模型可能一次返回多个 tool_call,但执行是串行的),不支持 checkpoint/恢复,不支持工具调用的取消。但对于一个终端 Agent 来说,这些取舍是合理的。
Agent 系统的复杂度不在循环本身,而在循环周围的东西——provider 怎么适配、工具怎么设计、权限怎么控制、上下文怎么压缩。这些会在后面的文章里逐个展开。
评论