让 Agent 记住上一次对话 — REPL 会话管理的工程实现
Agent 不是一次性的。你让它重构一个模块,做到一半网断了;你让它写测试,写了三个文件突然要开会;你让它调一个 bug,调到一半想明天再继续。这些场景下,如果关掉终端就意味着所有上下文全丢,那这个 Agent 就只能做"五分钟能搞定"的小事。
传统 CLI 工具没有"会话"概念——grep 不需要记住你上次搜了什么,git 的状态在 .git/ 目录里而不是在你的终端里。但 Agent 不一样,它的核心状态就是 messages 列表:所有的对话历史、工具调用结果、system prompt、压缩后的摘要——全在内存里。关掉进程,全没了。
BareAgent 的答案是:JSONL 持久化 + 会话隔离 + 斜杠命令一键恢复。
Session ID:时间戳 + 随机后缀
每个会话需要一个唯一标识。BareAgent 的 session ID 长这样:20250410-134502-123456-AbC3Xy。
_SESSION_ID_TIMESTAMP_FORMAT = "%Y%m%d-%H%M%S-%f"
def _generate_session_id(
transcript_mgr: TranscriptManager,
*,
reserved_ids: set[str] | None = None,
) -> str:
known_session_ids = set(transcript_mgr.list_sessions())
if reserved_ids:
known_session_ids.update(
session_id for session_id in reserved_ids if session_id
)
while True:
candidate = (
f"{datetime.now().strftime(_SESSION_ID_TIMESTAMP_FORMAT)}"
f"-{generate_random_id(6)}"
)
if candidate not in known_session_ids:
return candidate
为什么要这么设计?
时间戳在前——人类可读,而且文件系统排序就是时间顺序。你 ls .transcripts/ 一眼就能看到最近的会话是哪个。微秒精度(%f)进一步降低冲突概率。
随机后缀兜底——微秒精度在绝大多数场景下已经够了,但如果你同时开了两个 BareAgent 实例,时间戳可能撞车。6 位随机字符串(大小写字母 + 数字)提供额外的防冲突保障。
while True 循环——理论上还是可能冲突(虽然概率极低),所以还是 check 一下已有的 session ID 集合。reserved_ids 参数是给 /new 命令用的——新建会话时,当前会话的 ID 还没存到磁盘,需要额外传进来避免撞车。
JSONL 持久化:TranscriptManager
有了 session ID,下一步是把 messages 存到磁盘。BareAgent 用的是 JSONL 格式——一行一条消息,一个文件一次快照。
class TranscriptManager:
def __init__(self, transcript_dir: str | Path = ".transcripts") -> None:
self.transcript_dir = Path(transcript_dir)
self.transcript_dir.mkdir(parents=True, exist_ok=True)
def save(self, messages: list[dict[str, Any]], session_id: str) -> Path:
timestamp = datetime.now().strftime(_SAVE_TIMESTAMP_FORMAT)
path = self.transcript_dir / f"{session_id}_{timestamp}.jsonl"
with path.open("w", encoding="utf-8") as file:
for message in messages:
file.write(json.dumps(message, ensure_ascii=False))
file.write("\n")
return path
def load(self, session_id: str) -> list[dict[str, Any]]:
entry = self._get_session_entry(session_id)
with entry.path.open("r", encoding="utf-8") as file:
return [json.loads(line) for line in file if line.strip()]
为什么选 JSONL 不选 SQLite? 零依赖。.transcripts/ 目录可以直接 cat 查看、jq 过滤、cp 备份。对于一个终端工具来说,能用文件系统解决的就不要引入数据库。
文件命名是 {session_id}_{timestamp}.jsonl。同一个 session 可能有多次快照(每轮 agent loop 结束后都会保存),文件名里的时间戳让你能找到最新的那份。_get_session_entry 内部会取同一 session ID 下时间戳最大的文件。
每次保存都是全量覆写,不是增量追加。 听起来浪费,但考虑到 messages 列表可能被 compaction 彻底重组(老消息被摘要替换),增量追加根本没法做。全量写保证磁盘上的文件永远是一个完整的、可独立恢复的快照。
list_sessions 和 resume 的实现也很直白:
def list_sessions(self) -> list[str]:
latest_by_session: dict[str, datetime] = {}
for entry in self._iter_entries():
latest_by_session[entry.session_id] = max(
entry.timestamp,
latest_by_session.get(entry.session_id, datetime.min),
)
return [
session_id
for session_id, _ in sorted(
latest_by_session.items(), key=lambda item: item[1], reverse=True,
)
]
def resume(self, session_id: str | None = None) -> list[dict[str, Any]]:
target_session = session_id or self.get_latest_session()
if target_session is None:
raise FileNotFoundError("No saved transcripts found.")
return self.load(target_session)
按最近活跃时间倒序排列,/resume 不带参数默认恢复最近的会话。
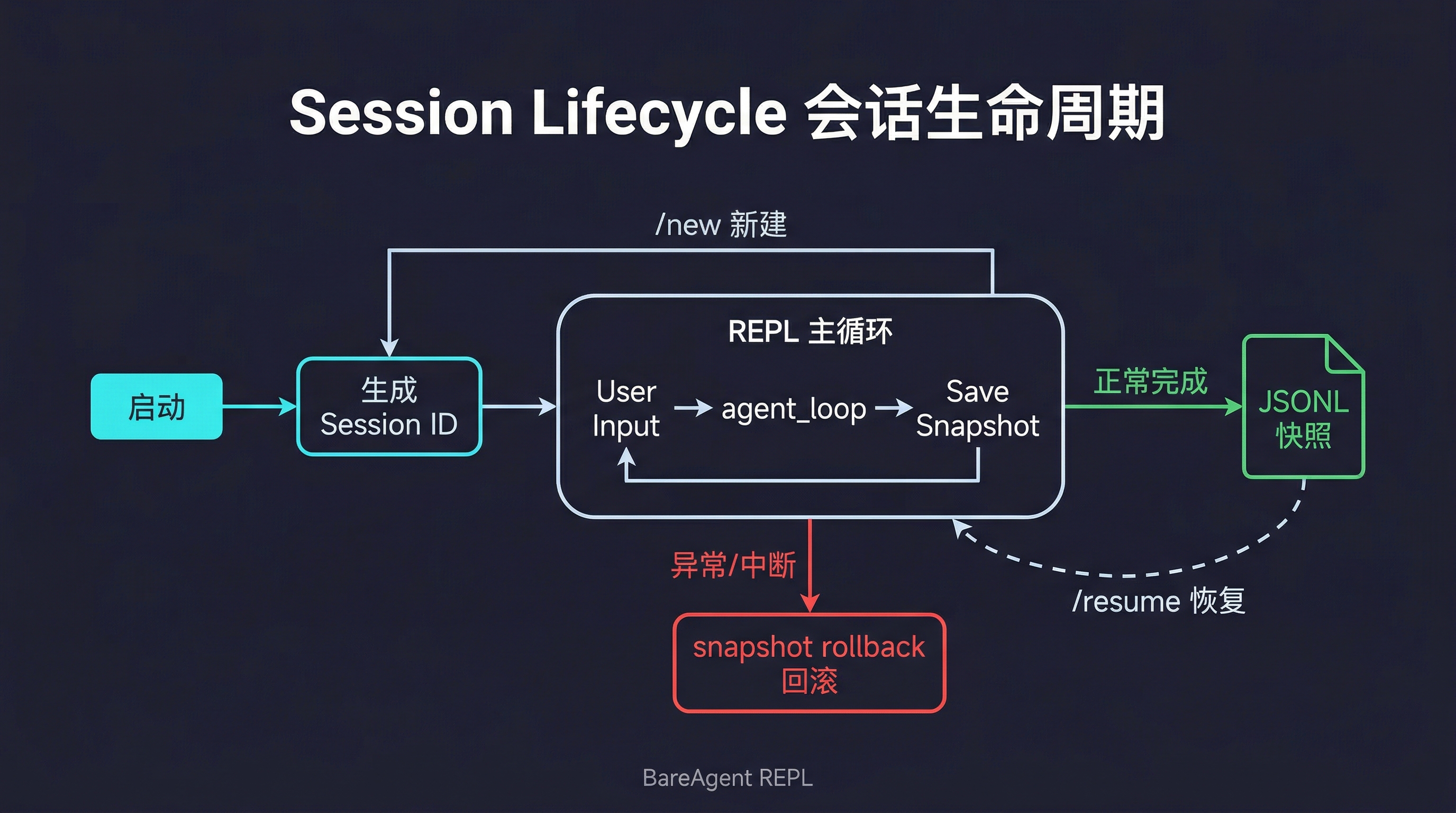
斜杠命令体系
BareAgent 的 REPL 提供了一组斜杠命令来管理会话:
| 命令 | 作用 |
|---|---|
/new /clear |
开始全新会话 |
/sessions |
列出所有历史会话 |
/resume [id] |
恢复指定会话(默认最近的) |
关键问题是:重置了什么 vs 保留了什么?
| 状态 | /new |
/resume |
|---|---|---|
| messages 列表 | 清空,重建 system prompt | 从磁盘加载 |
| TODO 任务 | 清空 | 不恢复(内存态) |
| session ID | 生成新的 | 切换到目标 session |
| compactor session | 切换到新 ID | 切换到目标 ID |
| mailbox | 新建,广播 SHUTDOWN | 切换到目标 session 目录 |
| spawned agents | 清空 | 清空 |
| permission 设置 | 保留 | 保留 |
| config 配置 | 保留 | 保留 |
| teammate 定义 | 保留 | 保留 |
注意 spawned agents 在两种情况下都会被清空——这是有意为之的,后面会详细解释。
恢复会话的完整流程
/resume 触发后,到底发生了什么?看一下实际代码:
if text == "/resume" or text.startswith("/resume "):
_, _, raw_session_id = text.partition(" ")
requested_session = raw_session_id.strip() or None
try:
restored_messages = transcript_mgr.resume(requested_session)
except FileNotFoundError as exc:
ui_console.print_error(str(exc))
continue
messages[:] = restored_messages
resumed_session = requested_session or transcript_mgr.get_latest_session()
if resumed_session is not None:
_set_compact_session_id(compact_fn, resumed_session)
_set_interaction_logger_session(interaction_logger, resumed_session)
message_bus, main_mailbox_cursor = _switch_session_mailbox(
workspace_path, resumed_session, current_bus=message_bus,
)
spawned_agents = {}
handlers = _build_handlers(
workspace_path=workspace_path,
todo_manager=todo_manager,
# ... 省略其他参数
messages=messages,
message_bus=message_bus,
spawned_agents=spawned_agents,
)
ui_console.print_status(f"Resumed session: {resumed_session}")
continue
分步解释:
1. 加载消息。 transcript_mgr.resume() 从磁盘读取 JSONL,返回完整的 messages 列表。messages[:] = restored_messages 用切片赋值就地替换——这很重要,因为 messages 这个列表对象被 handlers、compact_fn 等多个地方引用,换一个新列表会导致它们持有过期引用。
2. 切换 compactor session。 compactor 内部维护了一个 session ID,用于决定把压缩快照存到哪个 session 下。恢复会话时必须同步切换,否则压缩结果会存到错误的 session。
3. 切换 mailbox。 每个 session 有独立的 mailbox 目录(.mailbox/{session_id}/)。切换时先向旧 mailbox 广播 SHUTDOWN 消息通知所有 teammate,再创建新的 MessageBus 指向目标 session 的 mailbox。
4. 清空 spawned agents。 直接 spawned_agents = {},不尝试恢复已 spawn 的 agent。为什么?因为 spawned agent 是活着的线程——它们持有 provider 连接、绑定了特定的 mailbox cursor、可能正在等待 LLM 响应。从磁盘恢复一个"正在运行的线程"是不可能的。与其搞复杂的状态重建,不如保证干净状态:需要的 teammate 用户再 /team spawn 一下就好。
5. 重建 handlers。 这一步容易被忽略但很关键。handlers 是工具调用的执行函数集合,它们在构建时闭包了 messages 引用和 system prompt。如果不重建,handler 里缓存的 system prompt 还是旧会话的,子智能体(subagent)的 system prompt 也会错。
Nag Reminder:让 Agent 别忘了未完成的事
TODO 管理器维护了一组内存中的任务项(pending / in_progress / done)。问题是:Agent 在多轮对话中可能"忘记"自己还有未完成的任务——尤其是 context compaction 之后,旧的 TODO 相关对话被摘要替换了,Agent 可能不再意识到它还有事没做。
BareAgent 的解决方案是 nag reminder——在每次 compaction 前,动态注入未完成任务列表到消息流中:
def _refresh_nag_reminder(messages, nag_reminder):
# 先删掉所有旧的 nag reminder
messages[:] = [
msg for msg in messages
if not (msg.get("role") == "system"
and str(msg["content"]).startswith(_NAG_REMINDER_PREFIX))
]
if not nag_reminder:
return
nag_message = {
"role": "system",
"content": f"{_NAG_REMINDER_PREFIX}\n{nag_reminder.strip()}\n</nag-reminder>",
}
# 插入到最后一条 user message 之后
for index in range(len(messages) - 1, -1, -1):
if messages[index].get("role") == "user" and not is_tool_result_message(messages[index]):
messages.insert(index + 1, nag_message)
return
messages.append(nag_message)
插入位置的选择很讲究——放在最后一条 user message 之后,而不是 messages 列表末尾。这样 Agent 在处理用户最新请求时,会"顺便"看到未完成任务的提醒,比放在开头或末尾更自然,也更不容易被模型忽略。
这是一种"隐性上下文注入"模式:用户看不到这条消息(它是 system role),但 Agent 每次被调用时都会感知到。和第 6 篇讲的记忆压缩配合使用,即使旧对话被摘要了,关键任务状态也不会丢失。
错误恢复:snapshot-rollback 模式
LLM 调用可能失败——网络超时、API 限流、或者用户 Ctrl+C 中断。失败时的消息历史处于一个不确定状态:用户消息已经 append 进去了,但 Agent 的响应可能不完整。如果把这个残缺状态持久化到磁盘,下次 /resume 恢复出来的就是一个坏掉的会话。
BareAgent 的做法是 snapshot-rollback:
messages.append({"role": "user", "content": text})
snapshot_len = len(messages) - 1
try:
agent_loop(
provider=provider, messages=messages,
tools=tools, handlers=handlers,
# ...
)
_save_transcript_snapshot(transcript_mgr, messages, compact_fn)
except LLMCallError:
del messages[snapshot_len:]
ui_console.print_error("LLM call failed, please try again.")
except KeyboardInterrupt:
del messages[snapshot_len:]
ui_console.print_status("Agent loop interrupted.")
在 append 用户消息之前记住列表长度(snapshot_len),如果 agent loop 异常退出,就用 del messages[snapshot_len:] 把这一轮的所有消息全部回滚。只有成功完成一整轮循环后,才调用 _save_transcript_snapshot 持久化。
这保证了磁盘上的快照永远是一个"干净"的状态——不会出现半截对话、孤立的 tool_use 没有 tool_result、或者残缺的 assistant 响应。

团队状态与会话隔离
第 5 篇讲了 BareAgent 的多智能体架构。会话管理需要和团队系统配合,这里有一个关键区分:teammate 定义是全局的,agent 实例是 session 级的。
teammate 定义存在 .team.json 里——"谁是我的队友、它的角色是什么、用什么模型"。这些信息跨 session 共享,/new 不会清空。
但 spawned agent 实例是活着的线程,绑定到当前 session 的 mailbox。切换 session 时:
def _switch_session_mailbox(workspace_path, session_id, *, current_bus=None):
if current_bus is not None:
_broadcast_team_shutdown(current_bus)
message_bus = MessageBus(workspace_path / ".mailbox" / session_id)
message_bus.ensure_mailbox(MAIN_AGENT_NAME)
return message_bus, message_bus.latest_message_id(MAIN_AGENT_NAME)
先广播 SHUTDOWN 协议消息——所有监听旧 mailbox 的 autonomous agent 会收到通知并优雅退出。然后创建新的 MessageBus,指向新 session 的 mailbox 目录。这样不同 session 的团队通信互不干扰。
延伸思考
会话管理是 Agent 从"玩具"到"工具"的分水岭。一个不能保存和恢复状态的 Agent,只能做"坐在那里等它跑完"的任务;一个有完整会话管理的 Agent,可以融入你的日常工作流——做一半存着,明天继续,甚至在不同终端之间切换。
回顾这个系列:第 6 篇的 compaction 里 Compactor 需要 session ID 来隔离不同会话的压缩快照,第 7 篇的 debug log 里 InteractionLogger 需要 session ID 来隔离不同会话的调试日志。会话管理不是一个独立的功能,它是贯穿整个系统的基础设施。
从第 1 篇的 agent loop 到现在,BareAgent 的每一层都在解决"怎么让 Agent 在真实场景下可靠工作"的问题。REPL 会话管理解决的是最朴素的那个需求:关掉终端不等于丢掉工作。
评论