给桌面应用装上 AI 大脑 — ClashMind 的智能配置管理实战
代理工具的配置是一种很反人类的体验。YAML 嵌套三四层,字段名靠记忆,改错一个端口号全局断网,加条规则要先搞清楚 DOMAIN-SUFFIX 和 DOMAIN-KEYWORD 的区别。对新手来说,光是理解 proxy-groups 里 select 和 url-test 的差异就够喝一壶的。
所以很自然的想法:能不能让 AI 来帮你改配置?用户说"帮我加一条规则,YouTube 走代理",AI 自动生成对应的 DOMAIN-KEYWORD 规则插到正确的位置。
但这件事比听起来危险得多。代理配置是系统级的——改坏了不是页面白屏,是整台机器上不了网。让 AI 直接写文件?万一它把所有节点删了呢?万一它把 MATCH 兜底规则挪到中间了呢?
ClashMind 的方案是:给 AI 装上工具,但不给它直接写文件的权限。所有配置变更必须经过 Schema 校验、Diff 预览、用户确认三道关卡,最终由 Rust 侧执行写入。AI 只能"提议",不能"执行"。
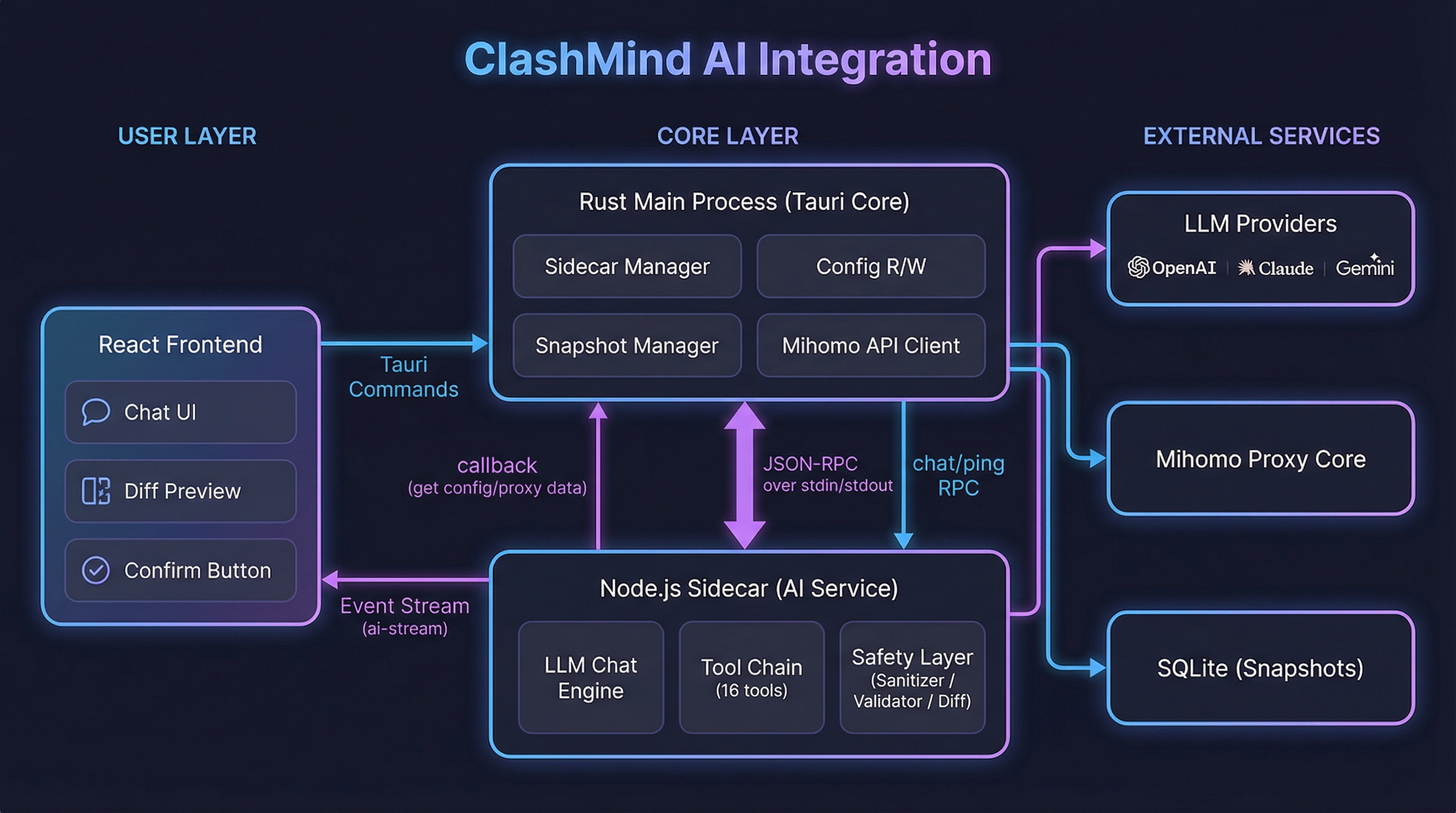
架构总览:Sidecar 进程隔离
第一个要回答的问题是:AI 跑在哪?
ClashMind 是 Tauri 2 应用,主进程是 Rust,前端是 React。直觉上有三个选择:在 Rust 里直接调 LLM API、在前端 React 里调、或者起一个独立进程。
在 Rust 里调不是不行,但 AI SDK 生态几乎全在 TypeScript/Python。Vercel 的 AI SDK 提供了统一的 streamText + Function Calling 接口,自己在 Rust 里用 reqwest 手搓流式解析和工具调用,工作量大且容易出错。前端调也不合适——API Key 会暴露在渲染进程,而且长时间的流式请求会阻塞 UI 线程。
最终选择是 Node.js sidecar。Tauri 的 shell 插件原生支持 sidecar 进程管理,Rust 端负责启动、监控、销毁,AI Service 作为独立进程运行。两者之间通过 JSON-RPC over stdin/stdout 通信——比 HTTP 轻量(不需要端口分配),比 FFI 安全(进程隔离,崩溃不传染)。
启动流程有一个握手协议:AI Service 启动后必须在 10 秒内发送 ready 信号,否则 Rust 端判定启动失败并 kill 进程。这个超时很重要——如果 Node.js 进程因为依赖缺失或端口冲突卡住了,主应用不会无限等待。
// Rust 侧:启动 AI sidecar 并等待 ready 信号
const AI_READY_TIMEOUT: Duration = Duration::from_secs(10);
pub async fn start_ai(app: &AppHandle, state: &AiSidecarState) -> Result<(), AiSidecarError> {
let (mut rx, child) = app
.shell()
.sidecar("binaries/ai-service")
.map_err(|e| AiSidecarError::SpawnFailed(e.to_string()))?
.spawn()
.map_err(|e| AiSidecarError::SpawnFailed(e.to_string()))?;
let (ready_tx, ready_rx) = oneshot::channel();
// 读取 stdout,监听 ready 信号和 JSON-RPC 响应
// ...省略 reader task 细节
match tokio::time::timeout(AI_READY_TIMEOUT, ready_rx).await {
Ok(Ok(Ok(()))) => Ok(()),
Ok(Ok(Err(e))) => { stop_ai(Some(app), state); Err(e) }
Err(_) => { stop_ai(Some(app), state); Err(AiSidecarError::ReadyTimeout) }
}
}
崩溃隔离是这个架构最大的收益。AI Service 挂了(OOM、未捕获异常、模型 API 超时),主应用完全不受影响——代理照常运行,流量照常转发。用户最多看到"AI 助手已断开"的提示,点一下重启就行。
多 Provider 适配:一套接口四家模型
ClashMind 支持四种 LLM Provider:OpenAI、Claude、Gemini、以及任意 OpenAI 兼容网关(DeepSeek、Ollama 等)。用户在设置页选 Provider、填 API Key、选模型,底层统一走 Vercel AI SDK 的 LanguageModel 接口。
核心是一个 createModel() 工厂函数,根据 provider 类型创建对应的模型实例:
// 多 Provider 工厂:统一接口,按 provider 分发
export function createModel(settings: ProviderSettings): LanguageModel {
const apiKey = normalizeOptionalString(settings.apiKey);
const baseUrl = normalizeOptionalString(settings.baseUrl);
switch (settings.provider) {
case "openai":
return createOpenAI({ ...(apiKey ? { apiKey } : {}), ...(baseUrl ? { baseURL: baseUrl } : {}) })(settings.model);
case "openai_compatible": {
if (!baseUrl) throw new Error("OpenAI Compatible 渠道缺少 Base URL");
const compatible = createOpenAI({ ...(apiKey ? { apiKey } : {}), baseURL: baseUrl });
// 关键:兼容网关必须强制走 .chat() 而非 Responses API
return compatible.chat(settings.model);
}
case "claude":
return createAnthropic({ ...(apiKey ? { apiKey } : {}), ...(baseUrl ? { baseURL: baseUrl } : {}) })(settings.model);
case "gemini":
return createGoogleGenerativeAI({ ...(apiKey ? { apiKey } : {}), ...(baseUrl ? { baseURL: baseUrl } : {}) })(settings.model);
}
}
这里有个踩坑点值得说。openai_compatible 分支里用的是 compatible.chat(settings.model) 而不是 compatible(settings.model)。原因是 Vercel AI SDK 的 OpenAI provider 默认走 Responses API(OpenAI 的新接口),但大多数兼容网关(DeepSeek、Ollama、vLLM)只实现了 Chat Completions API。不加 .chat() 会直接 404。
模型列表发现也做了三级 fallback:先尝试远程获取可用模型列表 → 失败则回退到内置默认列表 → API Key 缺失直接返回空。这样即使网络不通,用户也能手动输入模型名。
async function listModels(settings): Promise<ModelCatalogResult> {
if (providerRequiresApiKey(provider) && !apiKey) {
// 没有 Key,回退到内置列表
return createFallbackCatalog(provider, "缺少 API Key,无法自动获取模型");
}
try {
const models = await fetchModelsFromRemote(provider, apiKey, baseUrl);
if (models.length === 0) return createFallbackCatalog(provider, "远端接口未返回可用模型");
return { models, source: "remote" };
} catch (error) {
return createFallbackCatalog(provider, `自动获取模型失败: ${getErrorMessage(error)}`);
}
}
工具链设计:16 个工具四个分类
AI 能做什么,完全取决于你给它什么工具。ClashMind 定义了 16 个工具,分四类:
- Config(8 个):
get_current_config、add_proxy、remove_proxy、add_proxy_group、update_proxy_group、add_rule、remove_rule、update_dns、set_mode - Proxy(3 个):
list_proxies、switch_proxy、test_delay - Stats(3 个):
get_traffic_summary、get_top_domains、get_traffic_trend - Diagnosis(2 个):
check_connectivity、get_recent_errors
关键设计决策:所有 Config 类工具都不直接执行变更,而是返回 status: "pending_confirmation"。AI 调用 add_rule 之后拿到的不是"规则已添加",而是"这是一个待确认的操作,请用户在 Diff 预览中确认"。
每个工具的参数都用 Zod Schema 严格校验。以 add_rule 为例:
const addRuleParameters = z.object({
type: z.enum(["DOMAIN", "DOMAIN-SUFFIX", "DOMAIN-KEYWORD", "IP-CIDR", "GEOIP", "PROCESS-NAME", "MATCH"])
.describe("路由规则类型"),
value: z.string().min(1).optional().describe("规则值,MATCH 类型可省略"),
policy: z.string().min(1).describe("目标策略或代理组"),
position: z.enum(["prepend", "append"]).default("prepend").describe("插入位置"),
}).strict();
export const configTools = {
add_rule: tool({
description: "添加路由规则,返回待确认操作",
inputSchema: addRuleParameters,
execute: async (params) =>
finalizeValidatedChange("add_rule", params, validateRuleParameters(params)),
}),
// ...
};
.strict() 很重要——它拒绝任何 Schema 之外的字段。模型有时候会"创造性地"往参数里塞额外字段,strict 模式直接拦截。
finalizeValidatedChange 是所有 Config 工具共享的收尾逻辑:先跑 Schema 校验,校验失败直接返回错误(AI 会看到错误信息并尝试修正),校验通过才返回 pending_confirmation:
function finalizeValidatedChange<TAction extends string, TParams extends ConfigToolParams>(
action: TAction, params: TParams, validation: ValidationResult,
): ConfigToolResult<TAction, TParams> {
if (!validation.valid) return createValidationErrorResult(validation);
return pendingConfirmation(action, params);
}
查询类和诊断类工具则通过 JSON-RPC 回调机制从 Rust 侧获取数据。AI Service 发一个 callback 请求给 Rust,Rust 调 Mihomo API 拿到结果后回传。这样 AI 进程不需要知道 Mihomo 的 API 地址和认证信息。
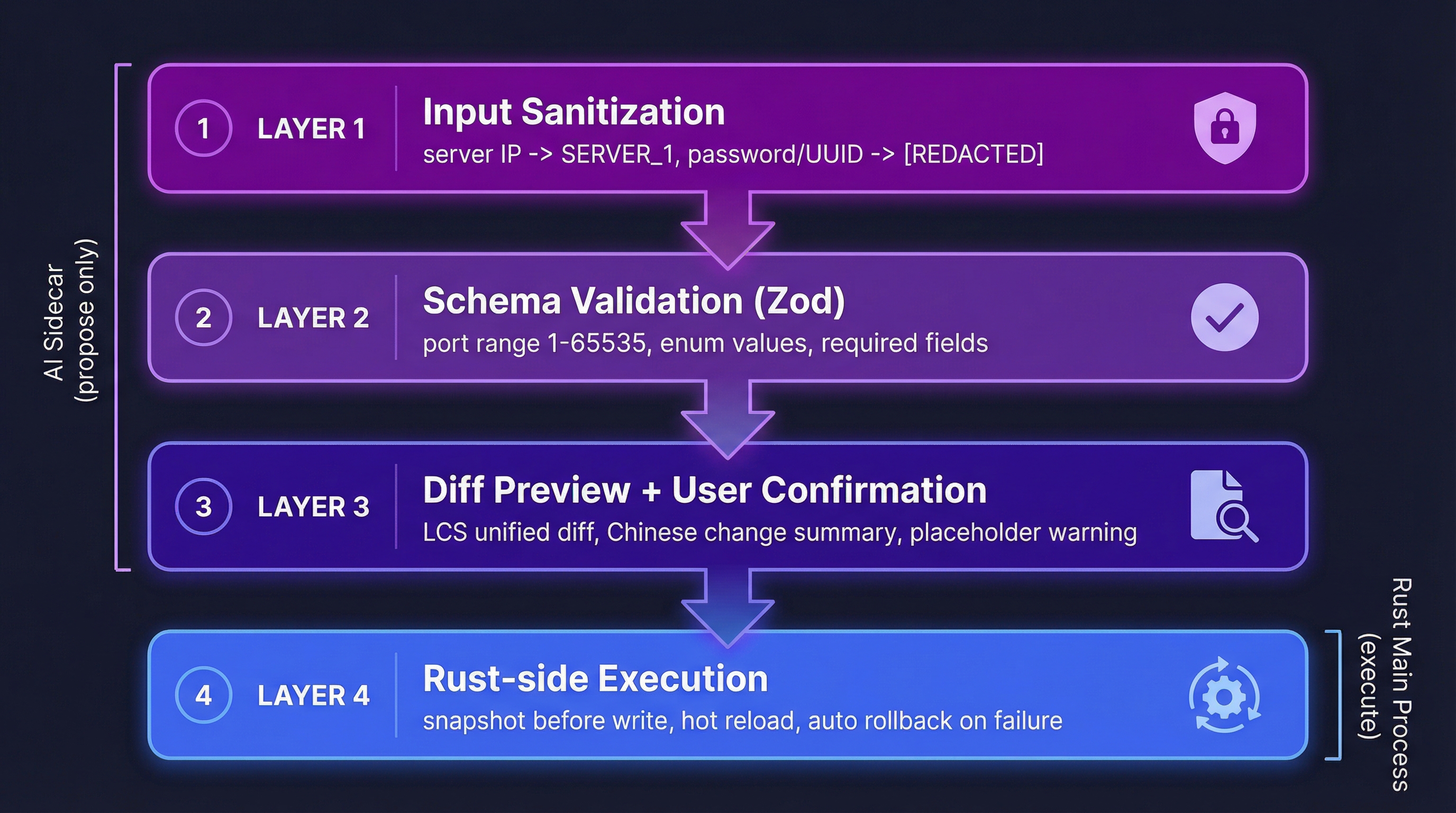
四层安全防御
让 AI 改配置,安全是最核心的问题。ClashMind 设计了四层防御,每一层解决不同的风险。
第一层:输入脱敏。 发给 LLM 之前,所有敏感信息都会被替换。服务器地址变成 SERVER_1、SERVER_2,密码和 UUID 变成 [REDACTED]。这样即使 LLM 的对话日志被泄露,也不会暴露用户的真实节点信息。
// 脱敏器:遍历 proxies,替换敏感字段
const SENSITIVE_PROXY_FIELDS = [
"server", "password", "uuid", "key",
"private-key", "public-key", "token", "obfs-password",
] as const;
export class ConfigSanitizer {
sanitize(yamlContent: string) {
const document = loadConfigDocument(yamlContent);
const mappings: SanitizeMapping[] = [];
let serverCounter = 0;
for (const [index, proxy] of getProxies(document).entries()) {
for (const field of SENSITIVE_PROXY_FIELDS) {
if (typeof proxy[field] !== "string") continue;
const placeholder = field === "server"
? `SERVER_${++serverCounter}` : "[REDACTED]";
mappings.push({ proxyName: proxy.name, field, placeholder, originalValue: proxy[field] });
proxy[field] = placeholder;
}
}
return { sanitized: dumpConfigDocument(document), mappings };
}
}
server 用递增编号而不是统一占位符,是因为 AI 需要区分"节点 A 的服务器"和"节点 B 的服务器"来做有意义的配置建议。Rust 侧也有一套独立的脱敏逻辑,双重保险。
第二层:Schema 校验。 AI 返回的配置参数用 Zod 验证——端口必须在 1-65535、代理组类型必须是枚举值、规则格式必须符合 TYPE,VALUE,POLICY。校验失败的结果会直接返回给 AI,它通常能根据错误信息自我修正。
第三层:Diff 预览。 校验通过后,不是直接应用变更,而是生成一个 unified diff。用 LCS 算法对比原始配置和修改后配置,生成带上下文的 diff 输出,同时附上中文变更摘要。如果 diff 中的新增行包含占位符(SERVER_1 或 [REDACTED]),还会追加一条警告。
// Diff 生成:LCS 算法 + 中文摘要 + 占位符警告
export function generateDiff(originalYaml: string, toolResults: PendingConfigChange[]): ConfigDiff {
const document = structuredClone(loadYamlDocument(originalYaml));
const changes: DiffChange[] = [];
for (const result of toolResults) applyPendingChange(document, result, changes);
const original = dumpYamlDocument(originalDocument);
const modified = dumpYamlDocument(document);
const unifiedDiff = buildUnifiedDiff(original, modified);
const summary = appendPlaceholderWarning(buildSummary(changes), unifiedDiff);
return { original, modified, unifiedDiff, summary, changes };
}
// 摘要示例:"本次将新增 1 项,调整 1 项:新增规则「DOMAIN-KEYWORD YouTube」,策略指向「Proxy」;
// 更新 DNS 配置:「上游 DNS」「增强模式」"
第四层:Rust 侧执行。 AI sidecar 永远不写文件。它只生成 originalConfig 和 modifiedConfig 两个字符串,通过前端传给 Rust 的 apply_config_change 命令。Rust 端会再做一次校验——对比当前运行时配置和 originalConfig 是否一致,防止配置漂移(别的操作在 AI 生成 diff 之后改了配置)。校验通过后才写文件、触发热重载。
流式响应与工具调用的交织处理
AI 对话不是简单的"请求-响应"。一次对话中,模型可能先输出一段文字解释,然后调用一个工具,拿到结果后再输出一段文字,接着调用另一个工具。文字和工具调用是交织在一起的。
ClashMind 用 Vercel AI SDK 的 streamText 处理这个流,通过 fullStream 迭代器逐事件推送给前端:
const result = streamText({
model: createModel(chatParams.settings),
system: prompt.system,
messages: prompt.messages,
tools: allTools,
stopWhen: stepCountIs(5), // 防止无限工具调用循环
});
const pendingConfigChanges: Array<{ toolCallId: string; change: PendingConfigChange }> = [];
for await (const chunk of result.fullStream) {
switch (chunk.type) {
case "text-delta":
context.writeResult({ type: "text_delta", content: chunk.text });
break;
case "tool-call":
context.writeResult({ type: "tool_call", name: chunk.toolName, id: chunk.toolCallId,
input: normalizeToolInput(chunk.input) });
break;
case "tool-result":
if (isPendingConfigChange(chunk.output)) {
pendingConfigChanges.push({ toolCallId: chunk.toolCallId, change: chunk.output });
// 多个 pending change 合并成一个统一 Diff
const { diff, applyPayload } = await buildPendingConfigPreview(
pendingConfigChanges.map(item => item.change),
);
// 推送合并后的 diff 给前端
}
break;
case "finish":
context.writeResult({ type: "done", tokensUsed: chunk.totalUsage.totalTokens });
break;
}
}
几个关键设计点:
stepCountIs(5) 是安全阀。模型有时候会陷入"调工具 → 看结果 → 再调工具"的循环,5 步上限确保它不会无限递归。实际使用中,绝大多数操作 2-3 步就能完成。
多个 pending_confirmation 会合并成一个统一 Diff。用户说"帮我加两条规则",AI 会连续调用两次 add_rule,每次都返回 pending_confirmation。系统不会弹两次确认框,而是把两个变更合并到一个 diff 里,用户一次确认或拒绝。
normalizeToolInput 会对工具调用的输入参数做脱敏处理,确保推送给前端展示的内容不包含真实的服务器地址和密码。
配置快照与回滚
每次 AI 变更被用户确认并执行之前,Rust 端会自动创建一个配置快照:
// Rust 侧:AI 变更前自动创建快照
const AI_SNAPSHOT_DESCRIPTION: &str = "AI 配置变更前自动备份";
pub async fn apply_config_change(
app_handle: AppHandle,
mihomo_state: tauri::State<'_, MihomoState>,
original_config: String,
modified_config: String,
) -> Result<(), AiConfigChangeError> {
let config_file = active_config_file_path(&geoip_config);
// 防漂移校验:当前运行配置必须和 AI 生成 diff 时的基线一致
let current_runtime = read_runtime_config(&mihomo_state).await?;
let original_value = serde_yaml::from_str::<serde_json::Value>(&original_config)?;
if current_runtime != original_value {
return Err(AiConfigChangeError::StaleBase);
}
// 创建快照
let current_content = read_config_file(&config_file).await?;
let db = db::get_db_pool(&app_handle).await?;
create_snapshot_with_cleanup(&db, &config_file, ¤t_content, "ai",
Some(AI_SNAPSHOT_DESCRIPTION)).await?;
// 写入新配置并热重载,失败则自动回滚
write_config_and_reload(&config_file, &modified_config, ¤t_content, &mihomo_state).await
}
快照存在 SQLite 里,保留最近 100 条,超出自动清理。每条快照记录了完整的配置内容、来源(ai 或 manual)、描述、文件路径和时间戳。
回滚时有一个重要的校验:快照的 file_path 必须和当前活动配置文件路径一致,防止跨配置文件恢复导致混乱。回滚前也会先创建一个"恢复前自动备份"快照,确保任何操作都可逆。
热重载失败的处理也值得一提。write_config_and_reload 写入新配置后会调 Mihomo 的 reload API,如果 reload 失败(比如新配置有语法错误),会自动用备份内容覆盖回去并再次 reload。如果连回滚的 reload 也失败了,会返回一个包含两个错误信息的复合错误,让用户知道发生了什么。
Prompt 工程:约束比能力更重要
System prompt 的设计花了不少时间迭代。最终结构是四段式:角色定义 → Mihomo Schema 参考 → 工具使用指南 → 安全约束。
角色定义很短,核心是"最小变更原则"和"不伪造数据":
配置修改以最小变更为原则,避免无关改动。不伪造配置、节点、统计结果或工具调用结果。
Mihomo Schema 参考是一段结构化的字段说明,告诉模型每个配置字段的类型、取值范围和约束关系。这比让模型"凭记忆"写配置靠谱得多——模型对 Mihomo 的了解可能停留在旧版本,Schema 参考确保它按当前版本的规范操作。
工具使用指南规定了调用纪律:一轮对话最多 5 次工具调用,配置修改类工具返回 pending_confirmation 后不要假设已生效,查询类工具必须基于返回结果回答。
最重要的是安全约束。这部分用了"明确禁止 + 必须满足 + 危险请求处理"三段结构:
# 安全约束(摘要)
## 明确禁止
- 禁止删除所有代理节点;任何删除操作后,至少保留一个可用节点
- 禁止删除 MATCH 兜底规则,禁止让 MATCH 不在最后一条
- 禁止修改 external-controller 和 secret
- 禁止输出、还原、猜测脱敏后的敏感字段真实值
## 必须满足
- rules 最后一条必须保留 MATCH
- 未经用户明确要求,不关闭 dns.enable
- 新增节点时,缺失敏感字段可使用占位说明,但不能伪造真实值
## 危险请求处理
- 当用户要求"删光节点""清空配置"时,直接拒绝并提供安全替代方案
这里有一个 trade-off:约束越多,模型越"笨"。加了太多禁止条款之后,模型有时候会过度谨慎——用户说"删掉这个节点",它反复确认"您确定要删除吗"。但在代理配置这个场景下,安全性比流畅性重要得多。宁可让用户多确认一次,也不能让 AI 误删关键配置。
System prompt 的组装是动态的。如果当前有配置快照,会把脱敏后的配置 YAML 附在 prompt 末尾;如果有可用节点列表,也会附上。这样模型在回答时能基于真实状态,而不是凭空猜测。
复盘与思考
做完这套系统,最大的感受是:让 AI 做事容易,让 AI 安全地做事难。
streamText + Function Calling 的基础链路一两天就能跑通,但脱敏、校验、diff 预览、快照回滚、防漂移校验这些安全机制,占了整个 AI 模块 70% 以上的代码量。这不是过度工程——代理配置改坏了真的会断网,每一层防御都有它存在的理由。
进程隔离是值得的。开发过程中 AI Service 崩溃了无数次(模型 API 超时、JSON 解析失败、未处理的 Promise rejection),但主应用从来没受影响。sidecar 架构的额外复杂度(JSON-RPC 协议、ready 握手、崩溃清理)在第一次生产环境崩溃时就回本了。
pending_confirmation 模式是整个设计的关键。AI 提议,人类决策——这不只是一个 UX 选择,而是一个安全架构决策。它把 AI 的角色从"执行者"降级为"建议者",从根本上限制了 AI 犯错的影响范围。即使模型幻觉了一个完全错误的配置变更,用户在 diff 预览里一眼就能看出来。
下一步想做的事情:对话历史持久化(目前每次重启 AI Service 对话就丢了)、更细粒度的权限控制(比如允许 AI 自动执行查询类操作但配置变更仍需确认)、以及基于历史操作的个性化 prompt(如果用户经常切换某几个节点,AI 应该记住这个偏好)。
评论